

أذهلت الصور البشرية الواقعية عالية الدقة التي تم إنشاؤها بواسطة أنظمة الذكاء الاصطناعي في السنوات الأخيرة الإنترنت. في حين أن تقنيات الرسوم المتحركة للصورة القائمة على الكلام المصممة لإضفاء الحيوية على هذه الوجوه قد ظهرت كمحور جديد في مجتمع البحث ، تميل الأساليب الحالية إلى النضال مع قضايا مثل اختلافات الوضع ، والتحكم العاطفي ، ومعالم الوجه.
في الورقة الجديدة SPACEx: رسوم متحركة للصورة تعتمد على الكلام مع إمكانية التحكم في التعبير، فريق بحث من NVIDIA يقدم SPACEx – إطار رسوم متحركة للصورة يعتمد على الكلام مع تعبير عاطفي يمكن التحكم فيه. ينتج عن النهج الجديد مقاطع فيديو عالية الدقة ومعبرة مع إمكانية التحكم في وضع الموضوع والعاطفة وكثافة التعبير ؛ ويحقق أحدث أداء للرسوم المتحركة للصور القائمة على الكلام.

يلخص الفريق مساهماتهم الرئيسية على النحو التالي:
- نحقق جودة عالية للرسوم المتحركة للصور القائمة على الكلام. يوفر SPACEx جودة أفضل من حيث FID ومسافات المعالم مقارنة بالطرق السابقة مع إنشاء مقاطع فيديو عالية الدقة.
- يمكن أن تنتج طريقتنا أوضاعًا واقعية للرأس مع القدرة أيضًا على نقل الأوضاع من فيديو آخر. كما يوفر إمكانية تحكم متزايدة من خلال استخدام معالم الوجه كمرحلة وسيطة ، مما يسمح بالتلاعب مثل الوميض والتحكم في نظرة العين وما إلى ذلك.
- بالنسبة لمجموعة المدخلات نفسها ، تسمح طريقتنا بمعالجة تسميات المشاعر وكثافتها المقابلة في فيديو الإخراج.


يأخذ SPACEx مقطع كلام وصورة وجه واحد كمدخلات ، ويمكن للمستخدمين زيادة تكييف الفيديو الناتج عن طريق إضافة ملصق عاطفي (سعيد ، حزين ، مفاجأة ، خوف). يقسم إطار العمل المهام إلى ثلاث مراحل لتحسين قابلية التفسير وإمكانية التحكم الدقيقة. في المرحلة الأولى ، Speech2Landmarks ، يتنبأ النموذج بحركات معالم الوجه في مساحة طبيعية بناءً على صورة الإدخال والكلام وتسمية العاطفة. في المرحلة الثانية ، مرحلة Landmarks2Latents ، تتم ترجمة معالم الوجه المطروحة لكل إطار إلى نقاط رئيسية كامنة. بالنظر إلى صورة الإدخال ومعالم الوجه المطروحة لكل إطار ، فإن نموذج الرسوم المتحركة للوجه المستند إلى الصورة المدروس مسبقًا ، face-vid2vid ، ينتج مقطع فيديو متحرك بدقة 512 × 512 في مرحلة التوليف النهائية.

يقدم الفريق تقنية جديدة لتكييف المشاعر تستخدم طبقات تعديل خطية مميزة (فيلم، Perez et al. ، 2017) لتمكين التحكم في التعبير العاطفي والشدة في الفيديو الذي تم إنشاؤه. في شبكة Speech2Landmarks ، يعدل FiLM ميزات الصوت وإدخال المعلم الأولي. في شبكة Landmarks2Latents ، يتم تطبيق FiLM على الصوت والمعالم ومدخل نقطة المفتاح الكامن الأولي.
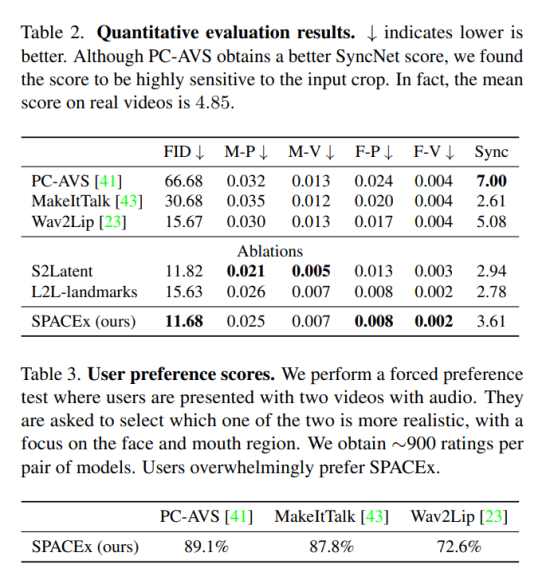
في دراستهم التجريبية ، قارن الفريق بين SPACEx و Wav2Lip و MakeItTalk وخطوط الأساس Talking Face-PC-AVS (PC-AVS) في العديد من مهام إنشاء الفيديو. في التقييمات ، حققت SPACEx أفضل أداء من حيث FID ومسافات المعالم مع إنشاء مقاطع فيديو عالية الدقة مع إمكانية التحكم في تعبيرات الوجه الفائقة.
يعتقد الفريق أن قدرات SPACEx يمكن أن تفتح آفاقًا جديدة واعدة في مؤتمرات الفيديو والألعاب وتوليف الوسائط.
تتوفر عينات من مقاطع الفيديو ومعلومات إضافية على موقع المشروع على الويب: https://deepimagination.cc/SPACEx/. الورقة SPACEx: رسوم متحركة للصورة تعتمد على الكلام مع إمكانية التحكم في التعبير قيد التشغيل arXiv.
مؤلف: هيكاتي هو | محرر: مايكل سارازين ، تشين زانج

نحن نعلم أنك لا تريد تفويت أي أخبار أو اكتشافات بحثية. اشترك في النشرة الإخبارية شعبية لدينا مزامنة Global AI الأسبوعية للحصول على تحديثات أسبوعية للذكاء الاصطناعي.

“هواة الإنترنت المتواضعين بشكل يثير الغضب. مثيري الشغب فخور. عاشق الويب. رجل أعمال. محامي الموسيقى الحائز على جوائز.”



